
Nota: alcuni link presenti in questo articolo sono affiliati. Questo significa che potremmo guadagnare una piccola commissione se decidi di acquistare tramite uno di questi link, senza variazioni di prezzo per te.
La ricerca online è cambiata del tutto e le tradizionali strategie basate su link building e scelta delle keyword sono soltanto un tassello del più vasto quadro del marketing online.
Ora strumenti come ChatGPT e le panoramiche AI di Google danno risposte dirette agli utenti, fatto che spesso rende inutile il clic su un sito web.
La sfida per i business si sposta: l’obiettivo attuale è venire citati dalle AI nelle risposte come fonti autorevoli.
Cos’è la SEO per LLM e perché sta cambiando la visibilità online
Il modo in cui le persone cercano informazioni sta cambiando, e con esso cambia anche il modo in cui i brand devono farsi trovare.
La metodologia SEO per i modelli linguistici di grandi dimensioni — GPT, Claude, Gemini — richiede un cambio di prospettiva radicale. L’obiettivo si sposta dal scalare posizioni in una lista di risultati al diventare parte della conoscenza che l’intelligenza artificiale usa per rispondere alle domande dei tuoi potenziali clienti.
Oggi i motori di ricerca affiancano sempre più strumenti capaci di offrire risposte dirette, contestualizzate e personalizzate. L’utente non scorre dieci link: ottiene una risposta. E quella risposta viene costruita a partire da contenuti che i modelli AI hanno elaborato e ritenuto affidabili.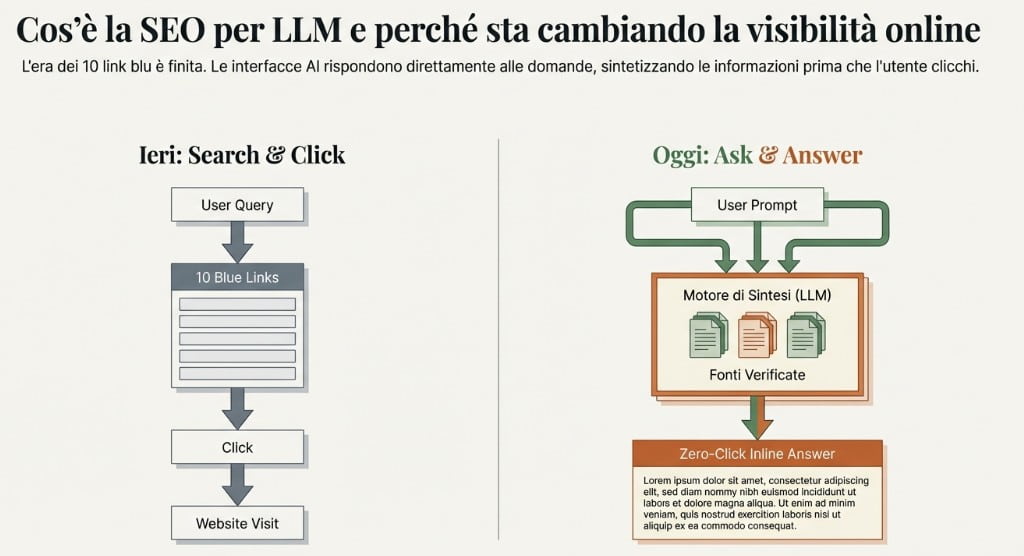
Per un brand, questo ha una conseguenza concreta: se i tuoi contenuti non sono comprensibili e citabili da un modello linguistico, rischi di non esistere in questa nuova conversazione.
La buona notizia? È una sfida che si può affrontare con metodo — e con le strategie giuste, il tuo marchio può diventare un riferimento autorevole anche nell’era dell’AI.
La SEO inferenziale è l’ottimizzazione pensata per aiutare l’LLM a fare inferenze corrette su ciò che sai, su chi sei e su cosa vale la pena citarti. Non si limita a keyword e snippet, ma lavora su struttura, chiarezza semantica, entità e relazioni tra concetti, così i modelli possono “ragionare” sul tuo contenuto come fonte autorevole
Perché ottimizzare un sito web per i LLM oggi
Gli utenti fanno domande sempre più articolate e naturali, e spesso trovano risposta direttamente nell’interfaccia AI — senza mai atterrare su un sito esterno. Questo cambia le regole del gioco: il traffico web tradizionale perde centralità, e con esso le metriche su cui molte aziende hanno costruito la propria strategia digitale.
Chi si muove prima ha un vantaggio concreto. I modelli linguistici tendono a fare riferimento alle spiegazioni più chiare e consolidate disponibili in rete: diventare quella fonte significa occupare uno spazio difficile da scalzare nel tempo.
C’è anche una ricaduta sulla reputazione. Quando un assistente AI cita il tuo brand come riferimento, agli occhi dell’utente è una validazione implicita — più credibile, in molti casi, di un annuncio pubblicitario.
Cosa sono i Large Language Models e come usano i contenuti web
GPT, Claude, Gemini: dietro questi nomi ci sono sistemi addestrati su miliardi di testi — libri, articoli, discussioni online — capaci di interpretare e generare linguaggio con una precisione che fino a pochi anni fa sembrava fantascienza.
La differenza rispetto a un motore di ricerca tradizionale è sostanziale. Un motore restituisce una lista di link e lascia all’utente il lavoro di trovare la risposta. Un modello linguistico sintetizza, contestualizza e risponde direttamente — trasformando ogni ricerca in una conversazione. L’attenzione si sposta dalla corrispondenza di parole chiave alla comprensione reale dell’intenzione dell’utente.
Il funzionamento di questi modelli combina due processi: un addestramento iniziale su grandi volumi di dati e il recupero di informazioni in tempo reale — una tecnica nota come RAG (Retrieval-Augmented Generation). Durante l’elaborazione, i testi vengono convertiti in strutture matematiche chiamate embedding: rappresentazioni che catturano il significato di un concetto anche quando le parole esatte non coincidono. Quando il modello costruisce una risposta, identifica entità rilevanti — marchi, prodotti, concetti — e le connette in una rete di relazioni semantiche.
I contenuti web sono la materia prima di questi sistemi. Un brand che produce dati originali, ricerche proprietarie o spiegazioni chiare e ben strutturate aumenta concretamente le probabilità di essere selezionato come fonte primaria.
Tieni a mente inoltre che molti crawler AI non eseguono JavaScript. Avere versioni HTML statiche dei propri contenuti non è un optional — è un requisito per essere letti e compresi correttamente.
Differenza tra SEO tradizionale e SEO per motori generativi
La SEO tradizionale e quella dedicata ai motori generativi rappresentano due strati di una strategia digitale moderna che si rivolgono a sistemi con logiche differenti.
La versione classica mantiene il suo focus principale sul posizionamento all’interno delle pagine dei risultati dei motori di ricerca come Google o Bing, con l’obiettivo di generare traffico diretto attraverso i click degli utenti.
Al contrario, l’ottimizzazione per i motori generativi punta a rendere un brand una fonte autorevole che l’intelligenza artificiale possa citare direttamente all’interno delle sue risposte sintetiche e discorsive.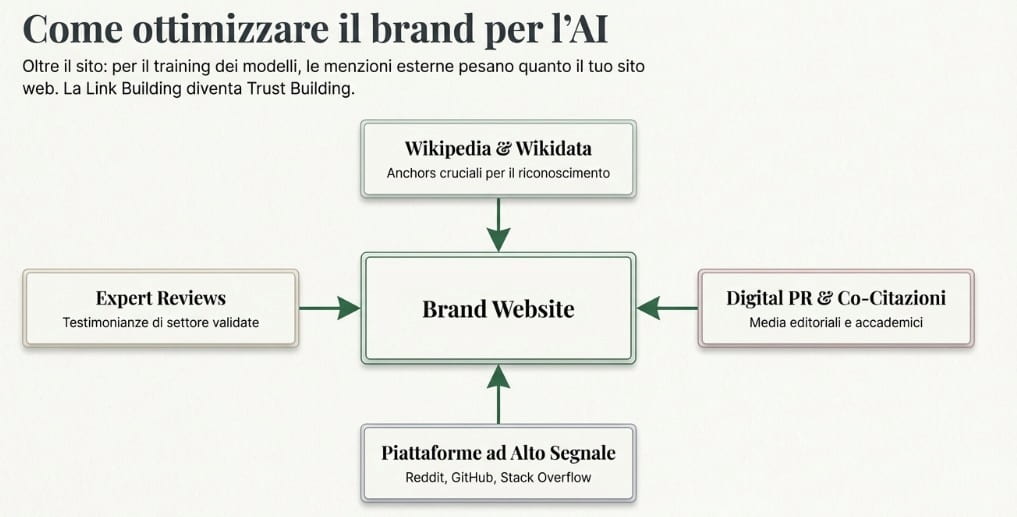
Mentre l’approccio tradizionale analizza il volume delle parole chiave e la forza dei backlink per scalare le classifiche, la SEO per l’IA mette al centro la chiarezza dei concetti e l’originalità delle informazioni fornite. I modelli linguistici non cercano semplici corrispondenze testuali esatte, ma interpretano il significato profondo e il contesto delle domande attraverso rappresentazioni vettoriali evolute. In questo nuovo panorama, la profondità informativa e la pertinenza dei contenuti diventano fattori più determinanti rispetto alla semplice ripetizione delle keyword.
Un’ulteriore distinzione risiede nell’importanza dei dati strutturati, che si trasformano in elementi fondamentali affinché l’intelligenza artificiale comprenda con precisione l’entità e le relazioni logiche presenti nel sito. La pianificazione dei contenuti si sposta quindi da una analisi basata esclusivamente sulle parole chiave verso una ricerca dell’intento profondo e delle necessità reali, con lo scopo di offrire soluzioni complete e verificate che i modelli possano rielaborare con fiducia.
Come i LLM selezionano e citano le fonti
I Large Language Models non operano come i crawler tradizionali, la cui logica è essenzialmente indicizzativa: scansione, estrazione di segnali di rilevanza, ordinamento. Gli LLM lavorano su un piano semantico più profondo, analizzando le relazioni tra entità all’interno di grafi di conoscenza strutturati e valutando la coerenza concettuale di un contenuto rispetto a un intero dominio tematico.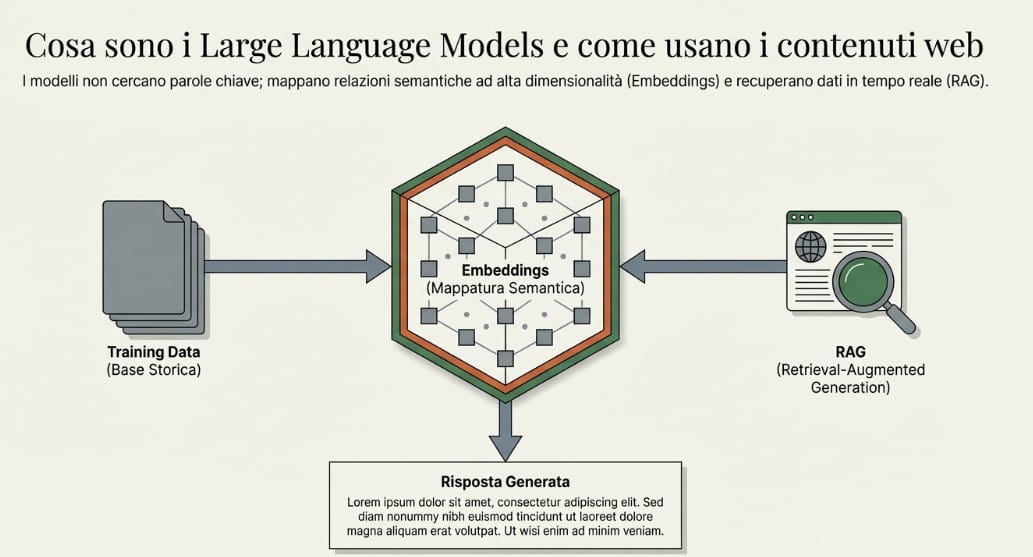
Molti dei sistemi AI oggi in uso — da Perplexity ai motori generativi integrati in Google e Bing — operano attraverso architetture RAG (Retrieval-Augmented Generation). Invece di affidarsi esclusivamente alla conoscenza acquisita in fase di addestramento, questi sistemi recuperano informazioni in tempo reale dal web e le integrano nel processo generativo. Il contenuto non viene semplicemente “trovato”: viene valutato, confrontato con altre fonti e selezionato in base alla sua utilità contestuale rispetto alla query dell’utente.
Nel processo di recupero, i testi vengono convertiti in vettori ad alta dimensionalità — gli embedding — che rappresentano il significato di un contenuto nello spazio semantico del modello. La pertinenza non si misura sulla corrispondenza letterale tra query e testo, ma sulla distanza vettoriale tra la rappresentazione della domanda e quella del contenuto disponibile. Un testo concettualmente denso e ben organizzato produce embedding più ricchi, aumentando la probabilità di essere recuperato anche per query formulate in modo diverso rispetto alle parole chiave su cui il contenuto è ottimizzato.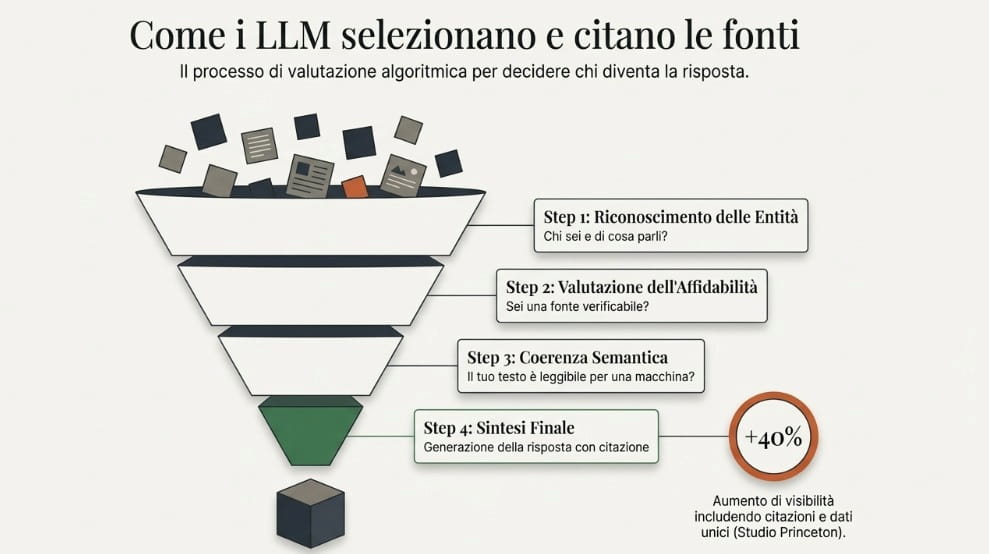
In questo framework, la selezione di un brand come fonte privilegiata segue una logica precisa: i modelli tendono a fare riferimento alla spiegazione più autorevole e completa disponibile su un determinato concetto, con una preferenza per i contenuti che combinano originalità informativa, struttura argomentativa chiara e verificabilità delle fonti citate. Essere i primi a pubblicare una trattazione esaustiva su un tema specifico — prima che lo spazio semantico venga occupato da competitor — è una delle leve più efficaci per consolidare la propria presenza nei sistemi generativi.
Segnali di affidabilità e autorevolezza
Il framework E-E-A-T — Experience, Expertise, Authoritativeness, Trustworthiness — nasce come criterio di valutazione qualitativa per i quality rater di Google, ma la sua logica sottostante si estende al modo in cui i modelli linguistici ponderano l’affidabilità di una fonte. La differenza è che, mentre nella SEO tradizionale l’E-E-A-T viene interpretato attraverso segnali proxy, nei sistemi generativi il modello valuta la coerenza complessiva della presenza digitale di un brand su scala più ampia e più granulare.
I backlink editoriali da domini autorevoli mantengono un ruolo rilevante — non solo come segnale di ranking tradizionale, ma come indicatore di grounding semantico per i modelli. Un collegamento da una fonte istituzionale o da una pubblicazione di settore non trasferisce solo autorità di dominio: contestualizza il brand all’interno di una rete di entità affidabili che il modello ha già codificato come attendibili.
A questo si aggiunge una dimensione che la SEO classica tende a sottovalutare: le menzioni non linkate. Le citazioni spontanee su forum professionali, community verticali, thread su Reddit o discussioni su LinkedIn contribuiscono a costruire quella che potremmo definire una reputazione semantica distribuita — un segnale che i modelli linguistici, addestrati su corpora che includono queste piattaforme, incorporano implicitamente nella propria valutazione di una fonte.
Ricerche proprietarie, casi studio con metodologia trasparente e dataset originali rappresentano uno degli asset più difficili da replicare e, per questo, tra i più valorizzati dai sistemi generativi. I modelli tendono a privilegiare informazioni ancorate a prove empiriche verificabili rispetto a sintesi editoriali prive di fonti primarie — una preferenza che riflette i criteri di qualità incorporati durante il fine-tuning e il processo RLHF.
Per un brand che opera in settori ad alta competitività informativa, investire nella produzione di contenuti basati su dati proprietari non è una scelta editoriale: è una decisione di posizionamento strategico nel nuovo ecosistema della ricerca generativa.
Contesto, chiarezza e utilità dei contenuti
Rendere un contenuto utile a un modello linguistico richiede un approccio alla struttura editoriale sostanzialmente diverso da quello ottimizzato per la lettura umana o per il crawling tradizionale. Il criterio guida è la granularità: ogni blocco di testo dovrebbe essere progettato per rispondere in modo autonomo a un’unità informativa specifica, senza che il modello debba ricostruire il contesto da sezioni adiacenti.
Una gerarchia di heading coerente — H1, H2, H3 usati con rigore logico e non estetico — non serve solo alla navigazione umana: fornisce al modello una mappa della struttura argomentativa del documento. I paragrafi brevi e autocontenuti aumentano la probabilità che un blocco di testo venga recuperato correttamente in un’architettura RAG, dove il sistema estrae chunk discreti di contenuto prima di sintetizzare la risposta. Un paragrafo che richiede il contesto del precedente per essere compreso è un paragrafo che rischia di essere mal interpretato o scartato.
L’inserimento di definizioni esplicite in prossimità dei concetti chiave — specialmente per terminologia tecnica o settoriale — riduce l’ambiguità semantica e migliora la qualità degli embedding generati dal modello sul contenuto. Questo vale in particolare per termini polisemici o per concetti che assumono significati diversi a seconda del contesto disciplinare. Un glossario strutturato non è un elemento accessorio: è un asset semantico che aumenta la precisione con cui il modello rappresenta il dominio tematico del sito.
L’implementazione di schema types appropriati — FAQPage, HowTo, Product, Article, Review — fornisce al modello un layer di contesto esplicito che va oltre il contenuto testuale. Mentre il testo comunica il significato, il markup dichiara la natura dell’informazione: una distinzione che diventa critica quando il modello deve decidere se una risposta è un’opinione, un dato verificabile o una procedura operativa. I sistemi basati su RAG utilizzano questi segnali per ancorare le informazioni recuperate a categorie semantiche predefinite, riducendo il rischio di allucinazioni contestuali.
Le tabelle comparative e i glossari svolgono una funzione che va oltre la leggibilità: rendono esplicite le relazioni logiche tra entità che nel testo narrativo rimangono implicite. Per un modello linguistico, una tabella ben costruita è una struttura dati già parzialmente formalizzata — più facile da codificare con precisione rispetto a una descrizione prosaica delle stesse relazioni. In domini ad alta densità informativa, come quello finanziario, legale o tecnologico, questa differenza si traduce in un vantaggio concreto in termini di citabilità e accuratezza delle risposte generate.
llms.txt e SEO: cosa è e a cosa serve
Proposto nel 2024 da Jeremy Howard — tra i fondatori di fast.ai — llms.txt è una specifica che definisce un file Markdown posizionato nella root del server, progettato per fornire ai modelli linguistici una rappresentazione sintetica e strutturata dei contenuti di un sito. La logica è analoga a quella di robots.txt e sitemap.xml, ma con un interlocutore diverso: non il crawler di un motore di ricerca, ma un sistema generativo che deve decidere in tempo reale quali fonti integrare nella propria risposta.
I modelli linguistici operano all’interno di una finestra di contesto finita. Quando un sistema RAG recupera contenuto da una pagina web, si trova a processare non solo il testo rilevante, ma l’intera struttura della pagina: navigazione, footer, script inline, banner, elementi di interfaccia. Questo rumore occupa token preziosi e può degradare la qualità del recupero semantico, aumentando il rischio che informazioni rilevanti vengano troncate o deprioritizzate.
llms.txt risolve questo problema a monte: invece di lasciare al modello il compito di estrarre segnale dal rumore, l’azienda fornisce direttamente una versione curata e gerarchizzata dei propri contenuti — con link alle risorse più rilevanti, descrizioni dei temi principali e indicazioni sulla struttura informativa del sito.
È importante essere precisi sullo stato di adozione: GPT, Gemini e Claude non hanno ancora integrato llms.txt come standard ufficiale nei propri sistemi di recupero. Perplexity AI ha dichiarato supporto esplicito, e diversi strumenti di settore — tra cui Yoast SEO e Semrush — hanno già implementato la generazione automatica del file. La specifica è pubblica e aperta su llmstxt.org, e la sua adozione da parte di player consolidati del mondo SEO suggerisce una traiettoria di legittimazione progressiva.
In assenza di uno standard universalmente adottato, llms.txt opera oggi come segnale di trasparenza e maturità tecnologica — una dichiarazione esplicita di come un’organizzazione vuole essere compresa dai sistemi AI. Per i siti con architetture complesse, grandi volumi di contenuto o domini tematici altamente specializzati, il file offre un canale diretto per comunicare priorità e struttura concettuale che il crawling automatico difficilmente cattura con la stessa precisione.
L’implementazione richiede un investimento tecnico minimo. Il ritorno potenziale — in termini di citabilità e accuratezza della rappresentazione del brand nei sistemi generativi — giustifica ampiamente l’adozione in fase precoce, prima che diventi una prassi consolidata e quindi meno differenziante.
Come comparire nelle ricerche AI senza perdere traffico
La tensione percepita tra ottimizzazione tradizionale e generativa è in larga parte falsa. Le due discipline condividono una base comune — contenuti autorevoli, struttura tecnica solida, reputazione digitale coerente — e divergono principalmente negli obiettivi finali e nei meccanismi di valutazione. Una strategia matura le integra, assegnando priorità in base al contesto competitivo e al comportamento del proprio segmento di utenza.
La snippability — termine che si sta consolidando nel lessico della GEO — descrive la capacità di un contenuto di essere estratto e riutilizzato in modo autonomo da un sistema generativo. Paragrafi autocontenuti, risposte dirette posizionate all’inizio di ogni sezione, strutture question-answer esplicite: questi elementi non compromettono l’esperienza di lettura umana, ma aumentano significativamente la probabilità che un chunk di contenuto venga selezionato in un’architettura RAG. La riscrittura in chiave snippable di pagine ad alto potenziale è spesso uno degli interventi a più alto ROI in una strategia GEO.
La visibilità nei sistemi generativi non si costruisce solo on-site. Le menzioni organiche in community verticali, forum professionali e discussioni su piattaforme come Reddit o LinkedIn alimentano il corpus su cui i modelli sono stati addestrati e continuano a essere aggiornati. Un brand che presidia questi spazi con contributi genuini — non con tattiche di seeding artificiale, sempre più facilmente riconoscibili — costruisce una reputazione semantica distribuita che i modelli incorporano implicitamente nella propria valutazione della fonte.
Le AI Overview e le risposte dirette dei sistemi generativi tendono a ridurre il volume complessivo di click su query informazionali. Questo è un dato di fatto che non ha senso minimizzare. Tuttavia, il traffico che raggiunge il sito dopo una risposta generativa arriva con un livello di qualificazione superiore: l’utente ha già ricevuto una sintesi, ha valutato la fonte citata e ha scelto di approfondire. Il tasso di conversione su questo segmento tende a essere più alto, e il posizionamento come fonte citata dall’AI genera un effetto reputazionale che si estende ben oltre il singolo click.
Errori comuni nella SEO per LLM
L’adozione di una strategia GEO non parte da zero: parte dalla qualità della fondazione esistente. I modelli linguistici non operano in un vuoto — accedono al web attraverso crawler, valutano l’autorità delle fonti attraverso segnali consolidati e privilegiano contenuti che soddisfano criteri di qualità che in larga parte coincidono con quelli della SEO tradizionale. Chi interpreta l’avvento dell’AI come un’occasione per aggirare questi fondamentali commette un errore strategico che si manifesta rapidamente in termini di citabilità.
Un dominio con autorità debole, problemi di crawlability o architettura informativa frammentata non diventa improvvisamente rilevante per un modello linguistico. L’authority di dominio, la qualità del profilo backlink e la solidità tecnica del sito rimangono segnali che i sistemi RAG utilizzano per ponderare l’affidabilità di una fonte nel momento del recupero. La GEO si costruisce su una SEO tradizionale funzionante, non in alternativa ad essa.
La ripetizione di parole chiave e sinonimi — tattica che in certi contesti mantiene ancora una residua efficacia nelle SERP tradizionali — è sostanzialmente irrilevante per i modelli linguistici e in alcuni casi controproducente. Gli LLM valutano la coerenza semantica complessiva di un testo: un contenuto costruito attorno alla densità delle keyword produce embedding meno ricchi rispetto a uno sviluppato con rigore argomentativo. Il segnale che i modelli cercano è la profondità concettuale, non la frequenza lessicale.
Posizionare informazioni rilevanti all’interno di componenti JavaScript renderizzati lato client, accordion non indicizzabili o menu a scomparsa è un errore tecnico con conseguenze dirette sulla citabilità. La maggior parte dei crawler AI — a differenza di Googlebot, che esegue JavaScript in fase di rendering — preferisce o si limita all’HTML statico. Qualsiasi contenuto che non sia accessibile nel DOM iniziale rischia di essere ignorato. La regola operativa è semplice: se un’informazione è strategicamente rilevante, deve essere presente nell’HTML statico della pagina.
I modelli linguistici sono addestrati a privilegiare informazioni verificabili e attribuibili. Un contenuto privo di firma autorevole, senza riferimenti a metodologie, fonti primarie o dati proprietari, è indistinguibile — agli occhi del modello — da migliaia di pagine simili generate per volumi. L’attribuzione esplicita dell’autore, con markup Person o Author in schema.org e una presenza digitale verificabile dell’autore stesso, contribuisce al segnale di expertise che i sistemi generativi utilizzano per qualificare una fonte. In settori YMYL — Your Money, Your Life — questo requisito diventa ancora più critico, poiché i modelli applicano soglie di affidabilità più stringenti prima di citare una fonte in risposta a query ad alto impatto decisionale.
Come monitorare la visibilità nei LLM
La misurazione della visibilità nei modelli linguistici è ancora un campo metodologicamente aperto. Non esiste uno strumento analogo a Google Search Console che certifichi in modo diretto e sistematico la citabilità di un sito nei sistemi generativi — una lacuna che riflette sia la novità del fenomeno sia la natura opaca dei meccanismi di selezione delle fonti. Ciononostante, è possibile costruire un framework di misurazione sufficientemente robusto combinando segnali diretti e indiretti.
Traffico referral da domini AI: il segnale più diretto disponibile
Google Analytics 4 permette di isolare le sessioni provenienti da domini come chat.openai.com, perplexity.ai, claude.ai o gemini.google.com attraverso segmenti di traffico referral dedicati. Questo dato non misura le citazioni complessive — la maggior parte degli utenti non naviga verso il sito sorgente — ma quantifica il sottoinsieme di utenti che, dopo aver ricevuto una risposta generativa, ha scelto di approfondire direttamente. Monitorare la crescita di questo segmento nel tempo, la qualità del traffico generato e le pagine di atterraggio più frequenti fornisce indicazioni concrete su quali contenuti stanno performando nei sistemi generativi.
Canary queries: verifica manuale sistematica
Le canary queries sono domande strategicamente costruite per verificare se e come un brand appare nelle risposte dei principali assistenti AI. La metodologia prevede di identificare le query per cui il brand dovrebbe essere una fonte autorevole — definizioni di settore, confronti competitivi, procedure specifiche — e testarle sistematicamente su ChatGPT, Perplexity, Claude e Gemini, documentando presenza, accuratezza della rappresentazione e posizione nella risposta. Eseguita con cadenza regolare e con un set di query standardizzato, questa pratica costituisce un audit qualitativo della propria visibilità generativa che nessuno strumento automatizzato riesce ancora a replicare con la stessa granularità.
Semrush è tra le prime piattaforme SEO consolidate ad aver integrato funzionalità specifiche per il monitoraggio della visibilità generativa, principalmente attraverso due offerte: l’AI SEO Toolkit — accessibile nei piani standard — e il pacchetto Enterprise AIO, rivolto a organizzazioni con esigenze di analisi più avanzate.
Il modulo di Ricerca Organica integra ora il rilevamento della presenza nelle AI Overview di Google, permettendo di identificare quali URL del proprio sito compaiono nei box generativi e per quali query. L’integrazione con il Position Tracking consente di confrontare il posizionamento tradizionale con la visibilità generativa sullo stesso set di keyword — un dato operativamente utile per identificare contenuti che rankano bene nelle SERP ma sono assenti nelle Overview, o viceversa, e calibrare le priorità di ottimizzazione di conseguenza.![]()
Il crawler di Site Audit è stato aggiornato per verificare la presenza e la corretta formattazione del file llms.txt nella root del dominio — un controllo che si affianca alle verifiche tecniche standard e segnala eventuali problemi di struttura che potrebbero compromettere la leggibilità del file da parte dei modelli.
Una delle funzionalità più rilevanti per chi opera in mercati competitivi è la possibilità di mappare la quota di visibilità nei sistemi generativi rispetto ai competitor diretti — identificando quali domini vengono preferenzialmente citati dall’AI per determinate categorie di prompt. Questo tipo di analisi permette di individuare gap di posizionamento generativo che non emergono dall’analisi tradizionale delle SERP.
Il pacchetto Enterprise AIO include funzionalità di analisi del sentiment per valutare se la rappresentazione del brand nelle risposte generative sia positiva, neutrale o negativa.
Semrush offre oggi uno degli ecosistemi più completi per chi vuole integrare la misurazione GEO nel proprio workflow SEO esistente, senza dover adottare strumenti separati.


7 giorni gratis per Semrush ONE ( SEO + AI visibility in una soluzione unica )