
Nota: alcuni link presenti in questo articolo sono affiliati. Questo significa che potremmo guadagnare una piccola commissione se decidi di acquistare tramite uno di questi link, senza variazioni di prezzo per te.
La ricerca semantica è un approccio che analizza l’intento e il contesto delle interrogazioni per fornire risultati basati sul senso dei concetti piuttosto che sulla forma delle parole. Tale evoluzione obbliga la SEO a privilegiare la qualità dei temi trattati e la rilevanza delle entità rispetto all’uso isolato delle vecchie parole chiave.
Cos’è la ricerca semantica e perché è centrale nella SEO moderna
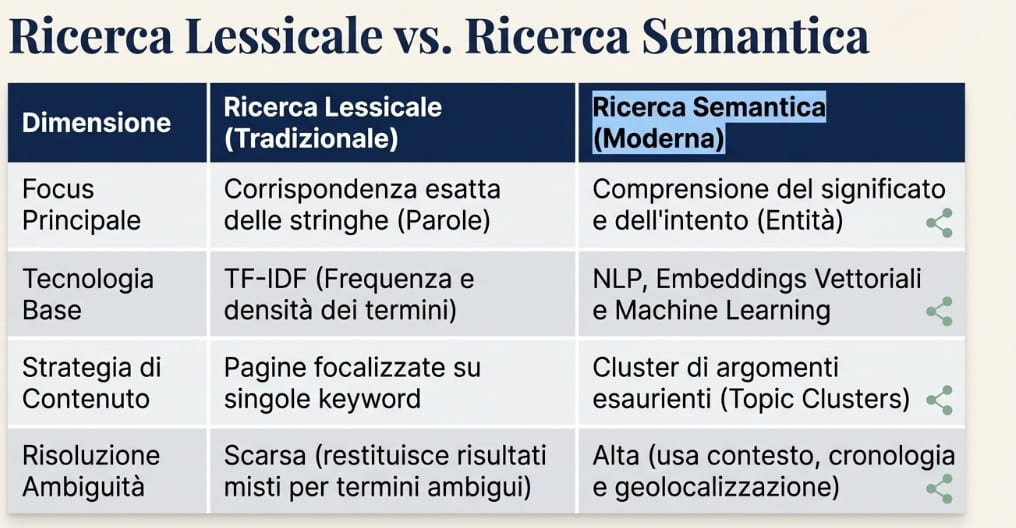
La ricerca semantica è una metodologia di recupero dei dati che interpreta il senso profondo e l’intenzione dell’utente, superando il limite storico della corrispondenza letterale tra termini e contenuti indicizzati. A differenza dell’approccio tradizionale basato sulle parole chiave, questo paradigma consente ai motori di ricerca di analizzare le relazioni tra parole, concetti ed entità, restituendo risultati coerenti con le reali necessità informative di chi effettua la query.
L’integrazione dell’intelligenza artificiale e del natural language processing ha reso possibile l’elaborazione del contesto con un livello di sofisticazione prima riservato alla comprensione umana. Il passaggio dalle sequenze di caratteri alle entità — oggetti del mondo reale dotati di attributi e relazioni reciproche — ha ridefinito le fondamenta stesse della SEO contemporanea. Strumenti come il Knowledge Graph di Google risolvono l’ambiguità semantica attingendo a segnali contestuali quali la posizione geografica dell’utente, la cronologia delle sessioni e le preferenze storiche, per disambiguare termini identici ma concettualmente distanti.
Questo scenario è ulteriormente accelerato dalla diffusione della ricerca vocale e delle interfacce conversazionali, che producono query articolate e sintatticamente complesse, strutturalmente incompatibili con la logica delle parole chiave esatte. Per chi progetta una strategia digital professionale, la risposta corretta non è l’ottimizzazione ripetitiva di una singola espressione, ma la costruzione di un’autorità tematica solida: copertura esaustiva di un dominio di conoscenza, architettura dei contenuti coerente e implementazione di dati strutturati che rendano leggibili alle macchine le connessioni logiche tra i concetti trattati.
A completare il sistema, modelli di machine learning come RankBrain e BERT affinano continuamente la pertinenza dei risultati sulla base del comportamento degli utenti e dei segnali impliciti di soddisfazione, trasformando ogni interazione in un dato di addestramento per le iterazioni successive.
Come funziona la ricerca semantica nei motori di ricerca
La ricerca semantica opera attraverso un’architettura che va ben oltre la scansione delle pagine alla ricerca di termini corrispondenti alla query. Il primo livello di elaborazione è affidato al Natural Language Processing (NLP), la branca dell’intelligenza artificiale che consente alle macchine di decodificare struttura grammaticale, riferimenti impliciti e sfumature del linguaggio umano — incluse ambiguità, sinonimie e variazioni di registro.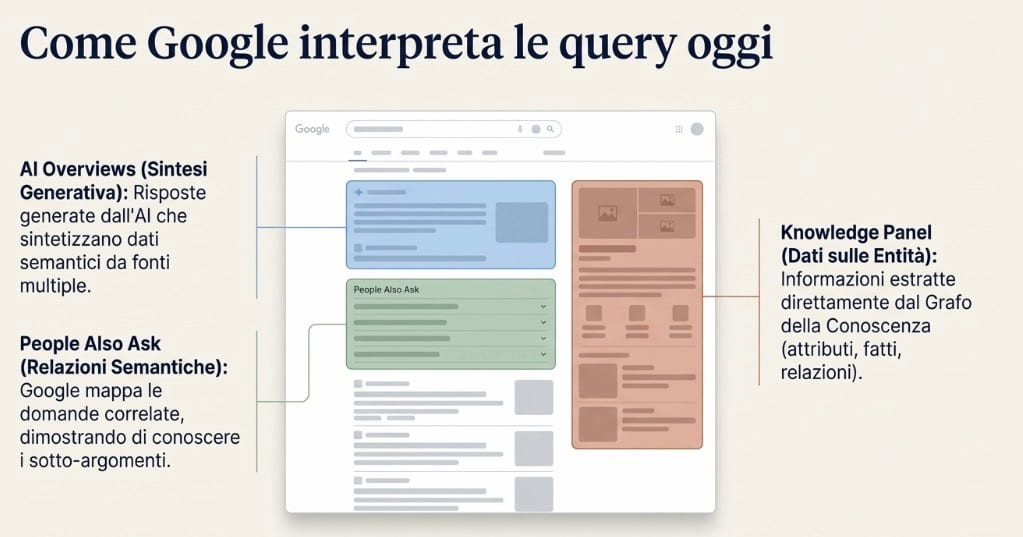
Il cuore tecnico del sistema risiede nelle vector embeddings: rappresentazioni matematiche del significato che collocano parole, frasi e documenti in uno spazio vettoriale ad alta dimensionalità. In questo spazio, la prossimità geometrica tra due punti corrisponde alla vicinanza semantica tra i concetti che rappresentano. Modelli come Word2Vec, GloVe e, più recentemente, le architetture transformer di BERT e GPT hanno progressivamente affinato la capacità di catturare relazioni contestuali complesse, superando i limiti dei modelli statistici precedenti basati sulla semplice co-occorrenza dei termini.
Su questo substrato si innesta il Knowledge Graph, il database strutturato con cui Google organizza miliardi di fatti su persone, luoghi, organizzazioni ed eventi in una rete di entità interconnesse da relazioni tipizzate. A differenza di un indice tradizionale, il Knowledge Graph non archivia documenti ma conoscenza: ogni nodo è un’entità con attributi verificati, ogni arco è una relazione semantica con un significato preciso. Questo consente al motore di rispondere a query complesse per inferenza, collegando informazioni distribuite su fonti diverse senza che esista un singolo documento che le contenga tutte.
Il risultato operativo è una funzione di pertinenza che non si limita alla presenza di singole parole chiave, ma valuta la coerenza tematica complessiva di un contenuto rispetto all’intento della ricerca. Per una strategia SEO professionale, questo implica che l’autorevolezza su un argomento si costruisce attraverso la densità e la qualità delle connessioni concettuali presenti in un sito, non attraverso la frequenza con cui una determinata stringa compare nel testo.
Dalle parole chiave al significato delle query
Il passaggio dalla logica delle “stringhe” a quella delle “cose” rappresenta la discontinuità più significativa nella storia dei motori di ricerca. Nel modello tradizionale, la rilevanza di un contenuto dipendeva dalla corrispondenza esatta tra la query e le occorrenze di una parola chiave nel testo — un approccio che premiava la ripetizione meccanica a scapito della qualità informativa.
Nel modello semantico, l’unità di analisi non è più la stringa di caratteri ma l’entità: un oggetto concettuale con attributi, relazioni e un posto definito all’interno di una rete di conoscenza strutturata.
La query expansion è la manifestazione più diretta di questo cambiamento. Quando un utente cerca un prodotto “economico”, il sistema riconosce autonomamente che “accessibile”, “low-cost”, “conveniente” e “a basso prezzo” esprimono la stessa intenzione, senza che queste varianti debbano comparire esplicitamente nel documento. Questo meccanismo libera la produzione dei contenuti dalla logica della copertura artificiale delle keyword e consente a una singola pagina tematicamente coerente di intercettare una costellazione di varianti semanticamente equivalenti. Sul piano pratico, significa che l’ottimizzazione forzata — la keyword stuffing o la moltiplicazione di pagine quasi identiche per catturare varianti lessicali — non produce più vantaggi competitivi e in molti casi genera penalizzazioni.
Algoritmi come RankBrain, introdotto da Google nel 2015 come primo sistema di machine learning applicato al ranking, e BERT, basato sull’architettura transformer e attivo dal 2019, operano su livelli distinti ma complementari. RankBrain interpreta query ambigue o mai viste in precedenza, proiettandole nello spazio vettoriale più vicino per trovare corrispondenze pertinenti. BERT analizza invece la struttura grammaticale completa della query — incluse preposizioni, congiunzioni e l’ordine delle parole — per distinguere sfumature di significato che un approccio basato sulle sole keyword non saprebbe cogliere.
La classificazione dell’intento in informativo, navigazionale e transazionale non è un esercizio tassonomico ma una variabile operativa: lo stesso termine può generare SERP radicalmente diverse a seconda del contesto in cui appare. Per chi progetta architetture di contenuto professionali, allineare il formato, la profondità e la struttura di ogni pagina all’intento dominante della query target è oggi una condizione necessaria al posizionamento, prima ancora che una scelta stilistica.
Il ruolo del contesto nella ricerca semantica
Il linguaggio umano è strutturalmente ambiguo: si stima che circa il 40% del lessico comune presenti significati multipli, e la disambiguazione — operazione cognitiva immediata per un interlocutore umano — richiede ai sistemi automatici un’architettura di segnali complessa e stratificata.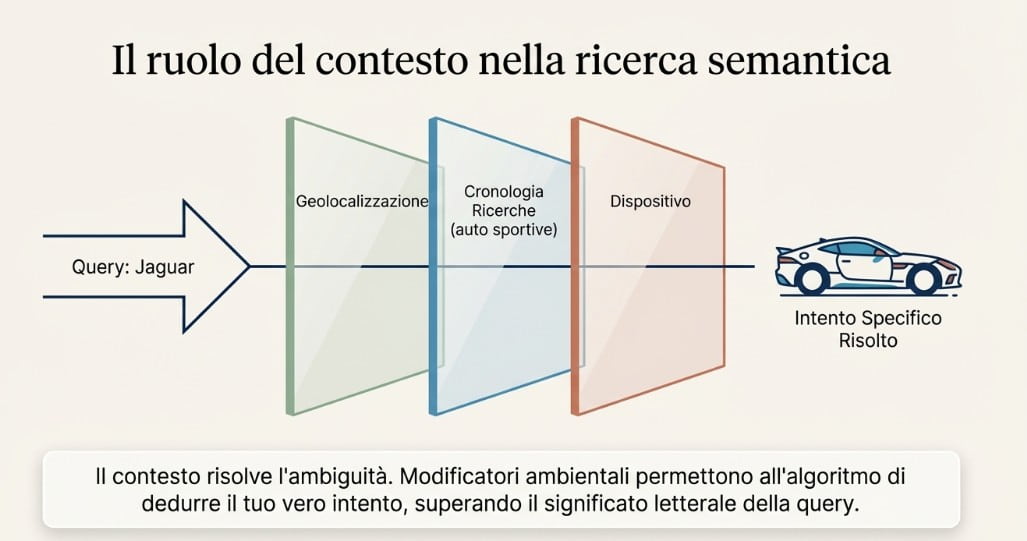
Il primo livello di risoluzione è contestuale in senso stretto. Quando un utente digita “Jaguar”, il motore non dispone di informazioni sufficienti per determinare se il riferimento sia all’animale, al marchio automobilistico o all’antico sistema operativo Apple. Entra allora in gioco un insieme di segnali esterni: la posizione geografica, la cronologia delle sessioni recenti, il tipo di dispositivo, le query precedenti nella stessa sessione e i trend di ricerca del momento. Questi segnali non agiscono in modo indipendente ma vengono ponderati congiuntamente per produrre un’inferenza probabilistica sull’intenzione più plausibile.
Il secondo livello è linguistico e opera attraverso le contextual embeddings — rappresentazioni vettoriali che assegnano a ogni parola un valore numerico diverso a seconda del contesto sintattico in cui appare. A differenza dei modelli statici come Word2Vec, in cui ciascun termine ha una rappresentazione fissa indipendente dall’uso, le architetture transformer come BERT generano embeddings dinamiche: la parola “Apple” in prossimità di “processore”, “iOS” o “App Store” occupa una posizione completamente diversa nello spazio semantico rispetto alla stessa parola affiancata a “raccolta”, “succo” o “varietà”. Questa capacità di rappresentazione contestuale consente al sistema di disambiguare anche query sintetiche o ellittiche, dove il significato è distribuito nell’intera frase piuttosto che concentrato in un singolo termine.
Il terzo livello è geografico-comportamentale e incide direttamente sulla composizione della SERP. Una ricerca come “macelleria” effettuata da un dispositivo mobile a Milano attiva la logica del local pack, che privilegia le attività fisicamente prossime all’utente con orari, recensioni e indicazioni stradali. La stessa query da un desktop senza geolocalizzazione attiva produce risultati strutturalmente diversi. Per le aziende con una presenza territoriale, questo significa che la visibilità locale dipende da fattori tecnici precisi: coerenza del profilo Google Business, struttura dei dati locali in schema.org e autorità delle citazioni nelle directory di settore.
Il risultato è un sistema di personalizzazione che non produce una risposta universale alla stessa query, ma calibra ogni SERP sull’individuo nel suo specifico momento informativo — trasformando la ricerca da un processo di recupero passivo a un’esperienza adattiva.
Come Google interpreta le query oggi
La personalizzazione profonda della SERP produce una conseguenza metodologica spesso sottovalutata: due utenti che digitano la stessa query in contemporanea possono ricevere risultati strutturalmente diversi. Posizione geografica, cronologia delle sessioni, dispositivo e ora della ricerca non si limitano a influenzare l’ordine dei risultati, ma determinano quali risultati compaiono, in quale formato e con quale profondità di risposta. Questo rende la misurazione del posizionamento organico un problema tecnico non banale: il ranking rilevato da un tool di monitoraggio è sempre un’approssimazione statistica, non una fotografia fedele dell’esperienza dell’utente finale.
Per i professionisti del web marketing, questa variabilità ha implicazioni dirette sulla progettazione delle campagne e sull’interpretazione dei dati. L’analisi della visibilità organica richiede quindi strumenti che simulino profili utente neutrali — browser in incognito, VPN geografiche, account non autenticati — e metodologie che distinguano il posizionamento strutturale dalla varianza indotta dal contesto individuale.
Sul piano strategico, la personalizzazione impone inoltre di ragionare per segmenti di intento piuttosto che per posizioni medie. Una pagina che performa bene per utenti in fase informativa può risultare invisibile per chi si trova in fase transazionale, anche sulla stessa keyword. Progettare contenuti che intercettino l’intento dominante del segmento target — e non l’intero spettro indifferenziato delle query — è la risposta operativa più efficace a un sistema che per definizione non mostra lo stesso risultato a tutti.
Evoluzione degli algoritmi verso la comprensione semantica
La storia della ricerca semantica è leggibile come una sequenza di salti architetturali, ciascuno dei quali ha spostato il confine di ciò che un motore di ricerca è in grado di comprendere.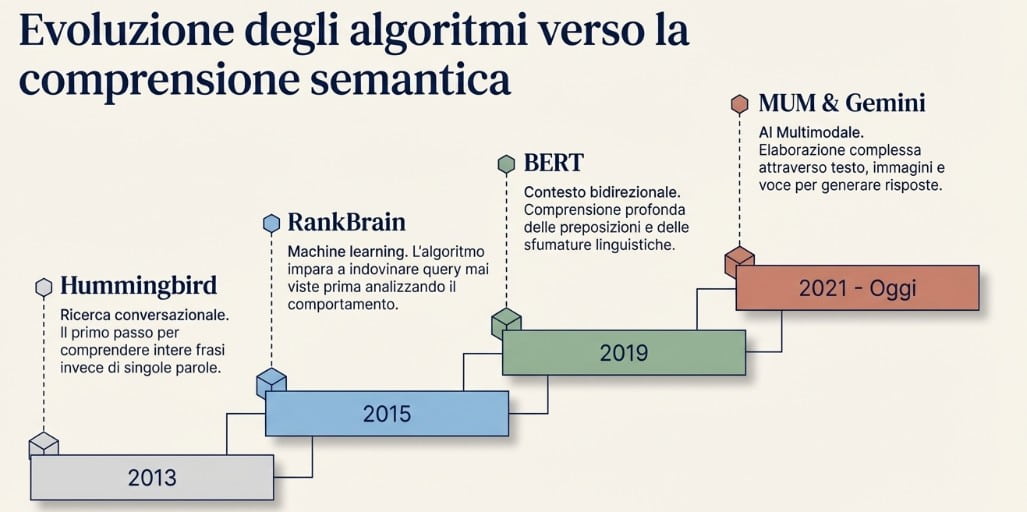
Il 2012 segna la prima discontinuità strutturale con il lancio del Knowledge Graph: un grafo di conoscenza che organizza miliardi di entità — persone, luoghi, opere, organizzazioni, concetti scientifici — in una rete di relazioni tipizzate. La novità non era la quantità di dati archiviati, ma il modello di rappresentazione: non documenti indicizzati ma fatti strutturati, interrogabili per inferenza e indipendenti dalla formulazione lessicale della query.
Nel 2013, l’aggiornamento Hummingbird ha riscritto il motore di parsing delle query, abilitando per la prima volta l’interpretazione di ricerche conversazionali nella loro interezza, anziché scomporle in keyword isolate. La tempistica non era casuale: la diffusione degli smartphone e dei primi assistenti vocali stava modificando la struttura sintattica delle query, rendendole più simili a domande in linguaggio naturale che a stringhe telegrafiche.
RankBrain, introdotto nel 2015, ha aggiunto una capacità qualitativamente diversa: l’apprendimento automatico applicato alle query ambigue o mai processate in precedenza. Anziché restituire un risultato nullo o approssimativo di fronte a formulazioni inedite, RankBrain proietta la query in uno spazio vettoriale e identifica le query semanticamente più prossime tra quelle già elaborate, trasferendo per analogia la logica di risposta.
BERT, rilasciato nel 2019, ha rappresentato il salto più profondo sul piano linguistico. L’architettura transformer su cui si basa processa ogni token in relazione bidirezionale con tutti gli altri elementi della frase — a destra e a sinistra simultaneamente — catturando dipendenze sintattiche a lungo raggio che i modelli sequenziali precedenti non riuscivano a modellare. La preposizione “per” in “farmaco per il dolore” e in “farmaco contro il dolore” produce rappresentazioni vettoriali diverse, con effetti diretti sul tipo di risultato restituito.
MUM (Multitask Unified Model), annunciato nel 2021, ha esteso questa capacità oltre i confini del testo e della lingua singola: il modello elabora simultaneamente informazioni provenienti da testi, immagini e video in oltre 75 lingue, ed è in grado di scomporre quesiti complessi in sotto-problemi logici da risolvere in sequenza. Gemini, l’architettura multimodale sviluppata da Google DeepMind e progressivamente integrata nei prodotti di ricerca a partire dal 2023, ha ulteriormente consolidato questa direzione, portando capacità di ragionamento multi-step direttamente all’interno della SERP attraverso le AI Overviews.
Per chi progetta strategie di contenuto, questa traiettoria ha un’implicazione precisa: ogni aggiornamento ha reso il sistema più capace di valutare la qualità concettuale di un documento e meno dipendente dai suoi attributi formali. La curva tecnologica premia la profondità, la coerenza tematica e la verificabilità delle informazioni — e penalizza in misura crescente i contenuti ottimizzati per le macchine di ieri.
Ricerca semantica ed entità
Le entità sono l’unità fondamentale della ricerca semantica moderna: non parole, ma oggetti concettuali del mondo reale — persone, luoghi, organizzazioni, prodotti, eventi, concetti astratti — dotati di identità univoca, attributi misurabili e relazioni verificabili con altre entità. La distinzione rispetto al modello basato sulle stringhe non è sfumatura terminologica ma differenza architettonica: una stringa è una sequenza di caratteri priva di significato intrinseco, un’entità è un nodo in una rete di conoscenza strutturata.
Il Knowledge Graph, lanciato da Google nel 2012, è l’infrastruttura che rende operativa questa logica. Ogni entità vi è rappresentata attraverso un identificatore univoco — il cosiddetto Knowledge Graph ID — che la distingue da qualsiasi omonimo o termine ambiguo indipendentemente dalla lingua o dalla formulazione usata nella query. “Tim Cook” non è la combinazione di un nome proprio e un verbo inglese, ma un nodo specifico con attributi verificati: ruolo professionale, affiliazione organizzativa, cronologia delle cariche, relazioni con altre entità rilevanti. Questa rappresentazione consente al sistema di rispondere a domande su Tim Cook anche quando la query non ne contiene il nome esplicito, per inferenza dalle relazioni nel grafo.
La struttura interna del Knowledge Graph si fonda su triple RDF (Resource Description Framework), nella forma soggetto-predicato-oggetto: ogni fatto è codificato come relazione orientata tra due entità. “Apple — produce — iPhone” e “iPhone 15 Pro — ha fotocamera — 48 megapixel” sono triple distinte ma collegate, che il sistema può attraversare per rispondere a query composite senza che esista un documento che le contenga tutte. Le coppie attributo-valore completano questa architettura per gli attributi scalari — prezzo, dimensioni, date, classificazioni — rendendoli interrogabili direttamente.
Le implicazioni per la visibilità nei sistemi generativi sono dirette e misurabili. Le AI Overviews e i modelli di risposta basati su Gemini attingono preferenzialmente a entità ben rappresentate nel Knowledge Graph, poiché la presenza strutturata di un’entità nella rete di conoscenza di Google costituisce un segnale di affidabilità e verificabilità. Un marchio, un professionista o un prodotto privo di una rappresentazione coerente nel grafo — o con attributi contraddittori distribuiti su fonti diverse — riduce significativamente la propria probabilità di essere citato nelle risposte generative, indipendentemente dalla qualità dei contenuti pubblicati sul sito. Per questa ragione, la gestione attiva della presenza nel Knowledge Graph — attraverso dati strutturati, profili verificati e coerenza delle informazioni nelle fonti autorevoli — è diventata una componente strategica della visibilità digitale professionale.
Dalle keyword alla SEO semantica
La SEO semantica non è un aggiornamento tattico della disciplina tradizionale ma una revisione del suo modello fondamentale. La pratica della ripetizione forzata delle keyword — density, posizionamento nel titolo, nell’URL, nei tag di intestazione — rispondeva a una logica di pattern matching in cui la frequenza era un proxy accettabile della rilevanza. In un sistema che ragiona per entità e relazioni concettuali, quella logica non solo è inefficace ma produce attivamente segnali negativi: un contenuto ottimizzato per le macchine di ieri è riconoscibile come tale dalle macchine di oggi.
Il Natural Language Processing e le architetture transformer come BERT e MUM hanno spostato il criterio di valutazione dalla forma alla sostanza concettuale. Le vector embeddings traducono questa capacità in termini operativi: ogni documento, frase e concetto viene rappresentato come un punto in uno spazio vettoriale ad alta dimensionalità, dove la distanza geometrica misura la vicinanza semantica. Due contenuti che non condividono nemmeno una parola possono risultare semanticamente equivalenti se occupano regioni prossime di questo spazio; due contenuti lessicalmente identici possono risultare distanti se affrontano lo stesso termine in contesti concettuali divergenti. Per un sistema di ranking, questo significa che la pertinenza di un documento si misura sulla coerenza tematica complessiva, non sulla densità di occorrenze di una stringa specifica.
La risposta strategica a questo modello è l’architettura a cluster tematici: una pagina pilastro che tratta un dominio di conoscenza in profondità, collegata a contenuti satellite che ne esplorano le dimensioni specifiche con altrettanta precisione. Questa struttura non serve solo alla navigazione interna ma comunica al motore la mappa concettuale del sito — chi tratta un argomento con questa sistematicità dimostra autorità tematica, non semplice presenza. La differenza rispetto alla proliferazione di articoli brevi su varianti di keyword è qualitativa: un sito con cento pagine superficiali su altrettante varianti lessicali occupa uno spazio semantico frammentato; un sito con dieci pagine profonde e interconnesse occupa un territorio concettuale coerente e difendibile.
I dati strutturati e lo schema markup completano questa architettura sul piano della comunicazione machine-readable. Il markup non aggiunge contenuto visibile ma rende esplicite al motore le relazioni logiche che nel testo naturale restano implicite: che un’entità è un prodotto con un prezzo e una disponibilità, che un articolo è la risposta a una domanda specifica, che un’organizzazione ha una sede verificabile e un insieme di servizi definiti. In un ecosistema dove le AI Overviews sintetizzano informazioni da fonti multiple, un contenuto semanticamente marcato offre al modello generativo appigli strutturali che aumentano la probabilità di essere estratto e citato correttamente.
Il principio unificante di questa evoluzione è la priorità del significato sulla forma: un ecosistema editoriale che soddisfa con precisione il bisogno informativo dell’utente, dimostra autorità verificabile su un dominio e comunica in modo strutturato le proprie relazioni concettuali è posizionato per performare in modo stabile, indipendentemente dalle variazioni algoritmiche future — che storicamente hanno sempre penalizzato le ottimizzazioni formali e premiato la qualità sostanziale.
Semrush ha strutturato la propria piattaforma attorno a un flusso di lavoro che copre l’intero ciclo della SEO semantica, dalla ricerca delle opportunità alla produzione editoriale fino al monitoraggio della visibilità nei sistemi generativi.
Il piano della visibilità nei sistemi generativi è presidiato dall’AI Visibility Toolkit, lo strumento più recente della suite e il più direttamente orientato al contesto attuale. La funzione centrale è il monitoraggio della presenza del brand nelle risposte di ChatGPT, Perplexity e nelle AI Overviews di Google — canali in cui la citabilità dipende da fattori diversi dal ranking organico tradizionale e che richiedono metriche di misurazione dedicate. I report sui gap semantici identificano le aree tematiche in cui i competitor ottengono una citazione più frequente o più autorevole dai modelli linguistici, traducendo un fenomeno difficilmente osservabile in un dato azionabile per la strategia editoriale.
Il valore complessivo della piattaforma non è dato solo dai singoli strumenti ma dalla continuità del flusso: dalla mappatura delle opportunità semantiche alla produzione di contenuti calibrati sull’intento, fino alla misurazione della visibilità nei canali generativi, Semrush offre un ambiente in cui le decisioni editoriali e tecniche possono essere ancorate a dati misurabili in ogni fase del processo.
7 giorni gratis per Semrush ONE ( SEO + AI visibility in una soluzione unica )
SEO tecnica e SEO semantica: differenze e integrazione
La distinzione tra SEO tecnica e SEO semantica è utile sul piano analitico ma rischia di diventare fuorviante sul piano operativo, perché i due ambiti non operano in sequenza ma in modo interdipendente: le scelte tecniche condizionano la leggibilità semantica del sito, e la struttura concettuale dei contenuti determina l’efficacia delle soluzioni tecniche.
La SEO tecnica governa le condizioni di accesso: velocità di caricamento, struttura degli URL, gestione dei redirect, configurazione del file robots.txt, profondità di scansione e budget di crawl. Quest’ultimo è un fattore spesso sottovalutato — Googlebot dispone di risorse limitate per ogni sito e le distribuisce in base a segnali di priorità. Un’architettura tecnica inefficiente disperde il budget di crawl su pagine a basso valore, lasciando parzialmente indicizzati i contenuti tematicamente rilevanti. Il risultato è che l’autorità semantica costruita attraverso la strategia editoriale non viene mai pienamente letta né valutata.
I link interni sono il punto di intersezione più diretto tra i due piani. Sul piano tecnico, distribuiscono il PageRank all’interno del sito e segnalano a Googlebot quali pagine meritano priorità di scansione. Sul piano semantico, comunicano le relazioni concettuali tra i contenuti: un link da una pagina pilastro a un contenuto satellite non è solo un percorso di navigazione ma un’affermazione esplicita di pertinenza tematica. La densità e la coerenza della rete di link interni è quindi sia un segnale di architettura tecnica che un elemento della mappa semantica del sito.
La velocità di caricamento e i Core Web Vitals — le metriche introdotte da Google nel 2021 per misurare la qualità dell’esperienza utente — agiscono come soglie di qualificazione: un sito al di sotto delle soglie tecniche accettabili subisce penalizzazioni che si sovrappongono ai segnali semantici, rendendo difficile isolare l’effetto delle ottimizzazioni contenutistiche nei dati di performance. Per chi gestisce progetti SEO complessi, questo significa che qualsiasi audit deve trattare i due piani in modo integrato: un problema tecnico irrisolto introduce rumore nella misurazione degli interventi semantici, e viceversa una strategia editoriale solida non compensa strutturalmente un’infrastruttura che impedisce al motore di leggerne i contenuti.
Al contrario, la SEO semantica sposta l’attenzione sul senso profondo dei contenuti e sulle relazioni logiche tra le entità, come persone, luoghi o concetti complessi. Il suo obiettivo principale risiede nella soddisfazione dell’intento di ricerca dell’utente e nella costruzione di una solida autorità tematica attraverso la copertura esaustiva di un intero argomento.
SEO semantica e contenuti di qualità
La qualità di un contenuto, nella logica della ricerca semantica, si misura sulla capacità di coprire un dominio di conoscenza con precisione e completezza — non sulla lunghezza del testo né sulla frequenza delle keyword. Il criterio operativo che i motori di ricerca applicano è la soddisfazione dell’intento: un contenuto performa in modo stabile quando risponde alla domanda esplicita dell’utente, anticipa le domande correlate che ne derivano e lo fa con un livello di profondità coerente con la fase del percorso informativo in cui si trova.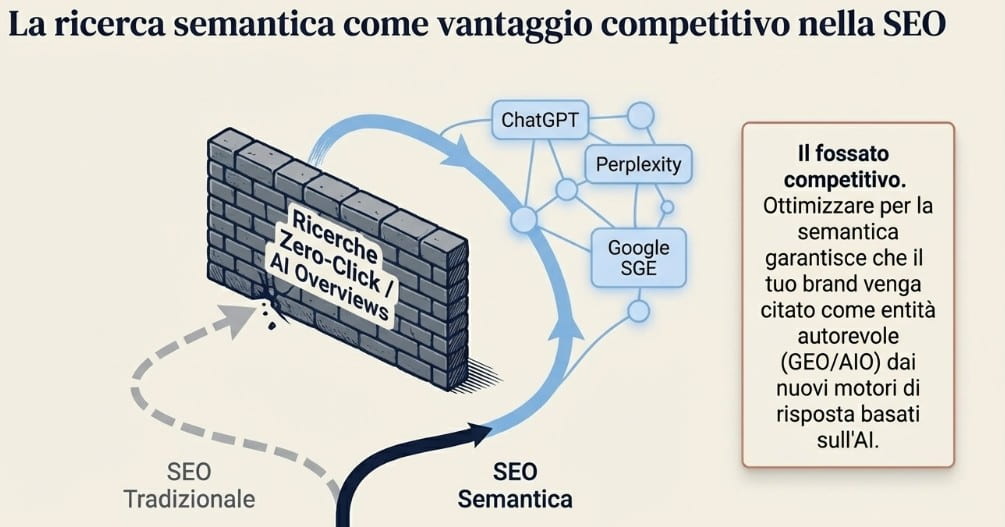
Questo principio ha una conseguenza diretta sull’architettura editoriale. Un articolo breve che tratta un sotto-argomento in modo superficiale non accumula autorità tematica: occupa spazio nell’indice senza costruire segnali di competenza verificabili. L’architettura a cluster tematici risponde a questa logica in modo strutturale — una pagina pilastro definisce il perimetro concettuale di un dominio e ne tratta le dimensioni fondamentali con ampiezza, mentre i contenuti satellite approfondiscono ciascuna dimensione con la granularità che una trattazione centrale non può permettersi. La rete di link interni che connette questi livelli non è solo un elemento di navigazione ma la rappresentazione esplicita della mappa concettuale del sito, leggibile tanto dagli utenti quanto dagli algoritmi.
La capacità di anticipare le domande successive è tecnicamente misurabile: le funzionalità “People Also Ask” e le query correlate nella SERP rivelano la struttura delle sessioni di ricerca reali — quali domande gli utenti pongono prima e dopo una determinata query. Integrare sistematicamente queste domande in un contenuto significa allineare la sua struttura al percorso cognitivo dell’utente, aumentando il tempo di permanenza, riducendo il tasso di rimbalzo e producendo i segnali comportamentali che i sistemi di machine learning interpretano come indicatori di soddisfazione.
Un elemento spesso trascurato in questo contesto è la distinzione tra completezza e ridondanza. Un contenuto che ripete le stesse informazioni in forme diverse per raggiungere una soglia di lunghezza percepita come autorevole produce l’effetto opposto: dilata il testo senza aumentarne la densità concettuale, e i modelli di valutazione della qualità — incluso quello alla base dei quality rater guidelines di Google — sono calibrati per riconoscere questa differenza. La metrica rilevante non è il numero di parole ma il rapporto tra la superficie testuale e il numero di concetti distinti e verificabili che il testo introduce.
Markup semantico e dati strutturati nella SEO
I dati strutturati sono il meccanismo attraverso cui un sito comunica esplicitamente al motore ciò che il testo naturale lascia implicito. Il linguaggio umano è efficiente per i lettori proprio perché si affida al contesto condiviso per disambiguare significati, omettere ridondanze e sottintendere relazioni logiche. Per un algoritmo, questo stesso meccanismo introduce incertezza: senza segnali espliciti, il sistema deve inferire il tipo di entità, i suoi attributi e le sue relazioni dal testo circostante, con margini di errore proporzionali alla complessità semantica del documento.
Schema.org risolve questo problema fornendo un vocabolario condiviso di tipi e proprietà — attualmente oltre 800 — che consente di annotare i contenuti in modo machine-readable. Dichiarare che un elemento è un’entità di tipo Organization con proprietà name, foundingDate, numberOfEmployees e sameAs che punta al profilo Wikidata corrispondente non aggiunge informazioni visibili all’utente, ma costruisce una rappresentazione formale che il motore può integrare direttamente nel Knowledge Graph senza passare per l’interpretazione del testo. Il formato JSON-LD, raccomandato esplicitamente da Google rispetto alle alternative Microdata e RDFa, è preferibile perché separa il markup semantico dal codice HTML, semplificando la manutenzione e riducendo il rischio di errori di implementazione.
La proprietà sameAs merita attenzione specifica: collegare un’entità ai suoi identificatori in database autorevoli — Wikidata, Wikipedia, VIAF, GND — è il meccanismo principale attraverso cui Google riconcilia le menzioni di un’entità distribuite su fonti diverse e consolida la sua rappresentazione nel Knowledge Graph. Per un marchio o un professionista che vuole costruire autorità verificabile nei sistemi generativi, questa riconciliazione è più rilevante di qualsiasi ottimizzazione testuale.
Sul piano della visibilità nella SERP, i dati strutturati aumentano la probabilità di qualificazione per le funzionalità avanzate — rich snippet, knowledge panel, sitelinks, FAQ, HowTo, product markup — ciascuna delle quali risponde a un tipo specifico di query e occupa posizioni visivamente prominenti nei risultati. Le AI Overviews attingono preferenzialmente a contenuti con markup semantico coerente perché la struttura esplicita riduce l’ambiguità nell’estrazione delle informazioni e aumenta la verificabilità delle affermazioni sintetizzate. Un contenuto privo di dati strutturati può comunque essere citato, ma compete in condizioni di svantaggio rispetto a fonti che hanno reso leggibile la propria architettura concettuale.
Tieni presente che un’implementazione efficace richiede coerenza tra i livelli: le entità dichiarate nel markup devono corrispondere a quelle trattate nel testo, gli attributi devono essere accurati e aggiornati, e le relazioni tra entità diverse all’interno dello stesso sito devono essere reciprocamente coerenti. Un markup contraddittorio o disallineato rispetto al contenuto visibile produce segnali di qualità negativi — Google Search Console li segnala come errori di implementazione — e può ridurre anziché aumentare la fiducia algoritmica nel documento.
La ricerca semantica come vantaggio competitivo nella SEO
Il vantaggio competitivo della SEO semantica non risiede nell’adozione di una tecnica specifica ma in un riposizionamento strutturale: il passaggio da una visibilità dipendente dalle fluttuazioni algoritmiche a una costruita su segnali di autorità che i sistemi di ranking — attuali e futuri — sono progettati per riconoscere e premiare.
Il primo beneficio misurabile è la qualità del traffico intercettato. Un contenuto ottimizzato per l’intento e per la copertura tematica attrae utenti in una fase avanzata del percorso informativo, con una domanda già definita e una propensione all’azione superiore rispetto a chi intercetta parole chiave ad alto volume ma bassa specificità. Le AI Overviews e i sistemi di risposta generativa amplificano questo effetto: citano preferenzialmente fonti che dimostrano comprensione profonda delle entità e delle loro relazioni, producendo una visibilità selettiva che tende a convertire meglio del traffico organico generico.
Il secondo vantaggio è l‘efficienza dell’architettura editoriale. Un contenuto semanticamente coerente e tematicamente esaustivo intercetta per definizione una costellazione di query correlate, varianti lessicali e domande satellite — senza che ciascuna richieda una pagina dedicata. Questo consolida l’autorità su un unico documento anziché distribuirla su una rete di pagine superficiali che si cannibalizzano a vicenda nei risultati di ricerca, un fenomeno tecnicamente noto come keyword cannibalization che penalizza la visibilità complessiva del dominio.
Il terzo vantaggio riguarda la presenza nei canali emergenti. I Large Language Model come ChatGPT, Perplexity e Gemini attingono a fonti che presentano informazioni strutturate, verificabili e semanticamente coerenti. La logica di citazione di questi sistemi non segue il ranking tradizionale ma privilegia la chiarezza concettuale e la densità informativa — caratteristiche che la SEO semantica produce come effetto diretto. Per i brand che vogliono mantenere visibilità in un ecosistema in cui una quota crescente delle query viene risolta senza click verso siti esterni, essere citabili dai modelli generativi è una dimensione della presenza digitale distinta e complementare al posizionamento organico classico.
Il quarto vantaggio è la stabilità nel tempo. Un brand riconosciuto come entità verificata nel Knowledge Graph di Google — con attributi coerenti, relazioni documentate e presenza consolidata nelle fonti autorevoli — accumula un tipo di fiducia algoritmica che non si azzera a ogni aggiornamento. La storia degli update di Google mostra una traiettoria coerente: ogni iterazione ha penalizzato le ottimizzazioni formali e premiato i segnali di autorità sostanziale. Investire nella costruzione di questa autorità significa posizionarsi sul lato giusto di una curva tecnologica il cui verso è prevedibile, anche quando i dettagli del prossimo aggiornamento non lo sono.